Configuration
The config.py enables you to customize GPT Researcher to your specific needs and preferences.
Thanks to our amazing community and contributions, GPT Researcher supports multiple LLMs and Retrievers. In addition, GPT Researcher can be tailored to various report formats (such as APA), word count, research iterations depth, etc.
GPT Researcher defaults to our recommended suite of integrations: OpenAI for LLM calls and Tavily API for retrieving real-time web information.
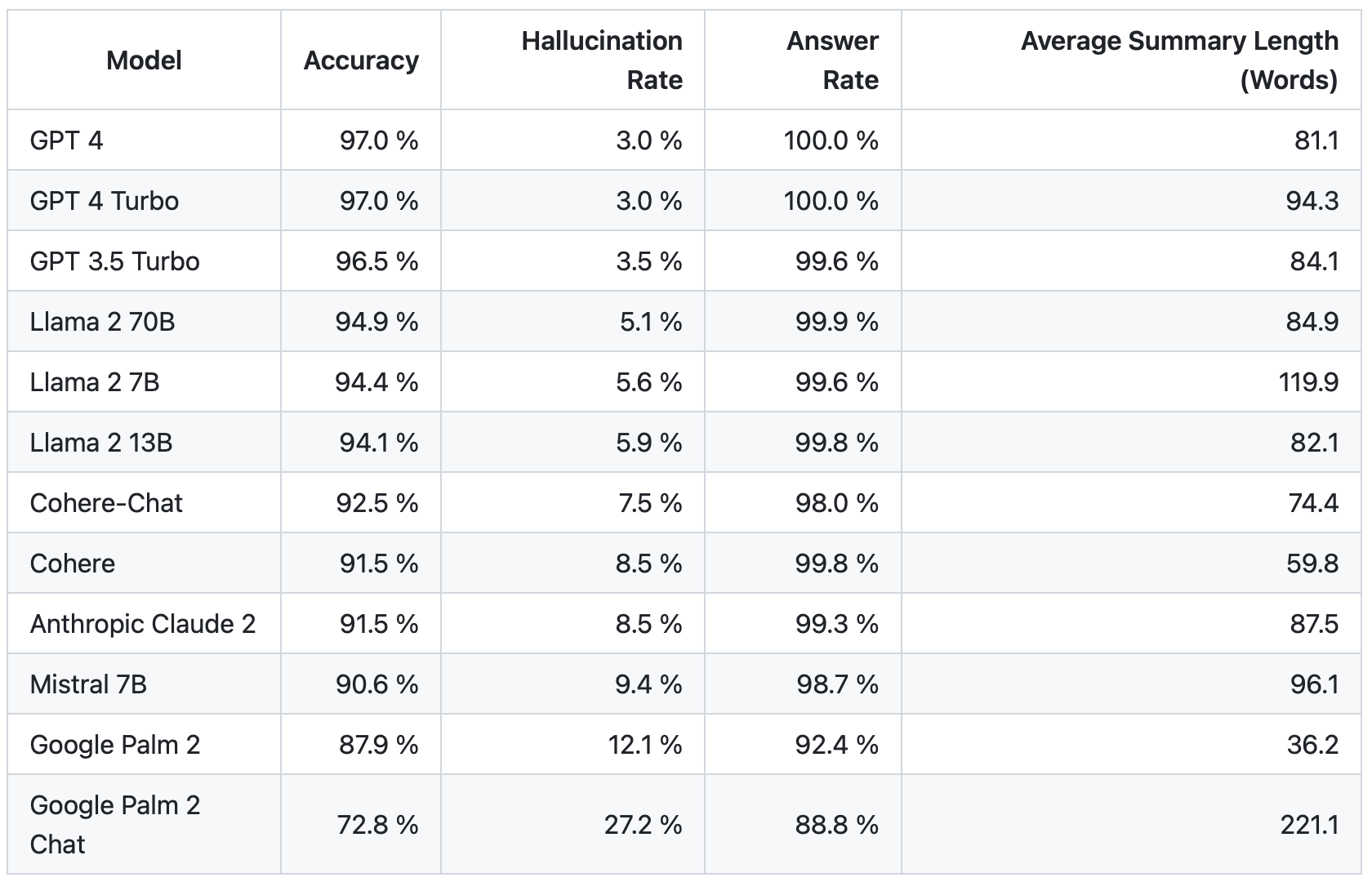
As seen below, OpenAI still stands as the superior LLM. We assume it will stay this way for some time, and that prices will only continue to decrease, while performance and speed increase over time.
The default config.py file can be found in /gpt_researcher/config/. It supports various options for customizing GPT Researcher to your needs.
You can also include your own external JSON file config.json by adding the path in the config_path param.
The config JSON should follow the format/keys in the default config. Below is a sample config.json file to help get you started:
{
"RETRIEVER": "tavily",
"EMBEDDING": "openai:text-embedding-3-small",
"SIMILARITY_THRESHOLD": 0.42,
"FAST_LLM": "openai:gpt-4o-mini",
"SMART_LLM": "openai:gpt-4.1",
"STRATEGIC_LLM": "openai:o4-mini",
"LANGUAGE": "english",
"CURATE_SOURCES": false,
"FAST_TOKEN_LIMIT": 2000,
"SMART_TOKEN_LIMIT": 4000,
"STRATEGIC_TOKEN_LIMIT": 4000,
"BROWSE_CHUNK_MAX_LENGTH": 8192,
"SUMMARY_TOKEN_LIMIT": 700,
"TEMPERATURE": 0.4,
"DOC_PATH": "./my-docs",
"REPORT_SOURCE": "web"
}
For example, to start GPT-Researcher and specify a specific config you would do this:
python gpt_researcher/main.py --config_path my_config.json
Please follow the config.py file for additional future support.
Below is a list of current supported options:
RETRIEVER: Web search engine used for retrieving sources. Defaults totavily. Options:duckduckgo,bing,google,searchapi,serper,searx. Check here for supported retrieversEMBEDDING: Embedding model. Defaults toopenai:text-embedding-3-small. Options:ollama,huggingface,azure_openai,custom.SIMILARITY_THRESHOLD: Threshold value for similarity comparison when processing documents. Defaults to0.42.FAST_LLM: Model name for fast LLM operations such summaries. Defaults toopenai:gpt-4o-mini.SMART_LLM: Model name for smart operations like generating research reports and reasoning. Defaults toopenai:gpt-5.STRATEGIC_LLM: Model name for strategic operations like generating research plans and strategies. Defaults toopenai:gpt-5-mini.LANGUAGE: Language to be used for the final research report. Defaults toenglish.CURATE_SOURCES: Whether to curate sources for research. This step adds an LLM run which may increase costs and total run time but improves quality of source selection. Defaults toFalse.FAST_TOKEN_LIMIT: Maximum token limit for fast LLM responses. Defaults to2000.SMART_TOKEN_LIMIT: Maximum token limit for smart LLM responses. Defaults to4000.STRATEGIC_TOKEN_LIMIT: Maximum token limit for strategic LLM responses. Defaults to4000.BROWSE_CHUNK_MAX_LENGTH: Maximum length of text chunks to browse in web sources. Defaults to8192.SUMMARY_TOKEN_LIMIT: Maximum token limit for generating summaries. Defaults to700.TEMPERATURE: Sampling temperature for LLM responses, typically between 0 and 1. A higher value results in more randomness and creativity, while a lower value results in more focused and deterministic responses. Defaults to0.4.USER_AGENT: Custom User-Agent string for web crawling and web requests.MAX_SEARCH_RESULTS_PER_QUERY: Maximum number of search results to retrieve per query. Defaults to5.MEMORY_BACKEND: Backend used for memory operations, such as local storage of temporary data. Defaults tolocal.TOTAL_WORDS: Total word count limit for document generation or processing tasks. Defaults to1200.REPORT_FORMAT: Preferred format for report generation. Defaults toAPA. Consider formats likeMLA,CMS,Harvard style,IEEE, etc.MAX_ITERATIONS: Maximum number of iterations for processes like query expansion or search refinement. Defaults to3.AGENT_ROLE: Role of the agent. This configures the behavior of specialized research agents. Defaults toNone. When set, it activates role-specific prompting and techniques tailored to particular research domains.MAX_SUBTOPICS: Maximum number of subtopics to generate or consider. Defaults to3.SCRAPER: Web scraper to use for gathering information. Defaults tobs(BeautifulSoup). You can also use newspaper.MAX_SCRAPER_WORKERS: Maximum number of concurrent scraper workers per research. Defaults to15.REPORT_SOURCE: Source for the research report data. Defaults towebfor online research. Can be set todocfor local document-based research. This determines where GPT Researcher gathers its primary information from.DOC_PATH: Path to read and research local documents. Defaults to./my-docs.PROMPT_FAMILY: The family of prompts and prompt formatting to use. Defaults to prompting optimized for GPT models. See the full list of options in enum.py.LLM_KWARGS: Json formatted dict of additional keyword args to be passed to the LLM provider class when instantiating it. This is primarily useful for clients like Ollama that allow for additional keyword arguments such asnum_ctxthat influence the inference calls.EMBEDDING_KWARGS: Json formatted dict of additional keyword args to be passed to the embedding provider class when instantiating it.DEEP_RESEARCH_BREADTH: Controls the breadth of deep research, defining how many parallel paths to explore. Defaults to3.DEEP_RESEARCH_DEPTH: Controls the depth of deep research, defining how many sequential searches to perform. Defaults to2.DEEP_RESEARCH_CONCURRENCY: Controls the concurrency level for deep research operations. Defaults to4.REASONING_EFFORT: Controls the reasoning effort of strategic models. Default tomedium.
Deep Research Configuration
The deep research parameters allow you to fine-tune how GPT Researcher explores complex topics that require extensive knowledge gathering. These parameters work together to determine the thoroughness and efficiency of the research process:
-
DEEP_RESEARCH_BREADTH: Controls how many parallel research paths are explored simultaneously. A higher value (e.g., 5) causes the researcher to investigate more diverse subtopics at each step, resulting in broader coverage but potentially less focus on core themes. The default value of3provides a balanced approach between breadth and depth. -
DEEP_RESEARCH_DEPTH: Determines how many sequential search iterations GPT Researcher performs for each research path. A higher value (e.g., 3-4) allows for following citation trails and diving deeper into specialized information, but increases research time substantially. The default value of2ensures reasonable depth while maintaining practical completion times. -
DEEP_RESEARCH_CONCURRENCY: Sets how many concurrent operations can run during deep research. Higher values speed up the research process on capable systems but may increase API rate limit issues or resource consumption. The default value of4is suitable for most environments, but can be increased on systems with more resources or decreased if you experience performance issues.
For academic or highly specialized research, consider increasing both breadth and depth (e.g., BREADTH=4, DEPTH=3). For quick exploratory research, lower values (e.g., BREADTH=2, DEPTH=1) will provide faster results with less detail.
To change the default configurations, you can simply add env variables to your .env file as named above or export manually in your local project directory.
For example, to manually change the search engine and report format:
export RETRIEVER=bing
export REPORT_FORMAT=IEEE
Please note that you might need to export additional env vars and obtain API keys for other supported search retrievers and LLM providers. Please follow your console logs for further assistance. To learn more about additional LLM support you can check out the docs here.